
Digging Deeper with htracr
Saturday, 27 November 2010
There’s a lot of current activity on the binding between HTTP and TCP; from pipelining to SPDY, the frontier of Web performance lives between these layers.
To get more visibility in exactly what’s happening down there, I decided to throw together a little tool to show how HTTP uses TCP: htracr.
In a nutshell, It’s a packet sniffer written in JavaScript, thanks to node_pcap, and it uses RaphaelJS to visualise what’s going on. It’s still very young (lots of bugs to fix, lots of features to add), but I thought I’d share some early observations that it’s made possible.
Twiddling the Initial Congestion Window
The guys over at Google have been banging the drum for increasing the Initial Congestion Window (initcwnd) in TCP, so that slow start isn’t so… slow. Their recommended value is 10*MSS, so I decided to give that a try and see what happened.
This is a full fetch of the background image on mnot.net’s home page, from Australia to Texas:
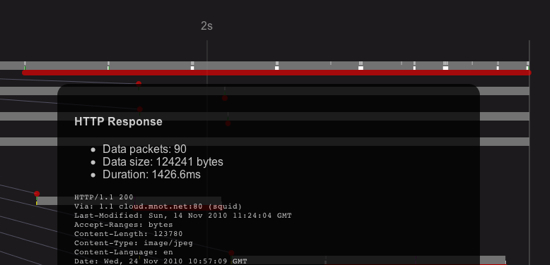
As you can see, it takes almost 1.5 seconds to transfer about 120K, which translates to about six round trips (given that my RTT is about 250ms). Note that this isn’t slow because I don’t have good bandwidth here (it’s about 15Mbits); it’s because TCP slow start is starting conservative, and this request is fairly early in the connection.
Now, if we tune the initcwnd to 10*MSS on the server side, we see something different:
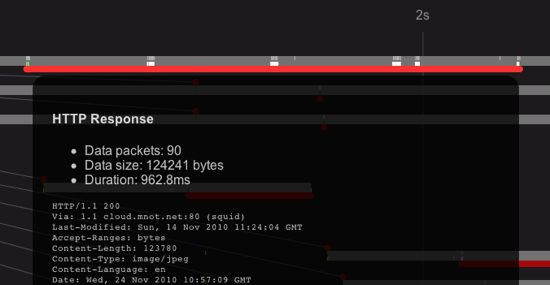
Same 90 packets, same content, but less than a second, or roughly four round trips. Nice.
There are, of course, all kinds of caveats around this. I haven’t changed the client initcwnd, so this only helps responses. Furthermore, I’m just starting to collect data about TCP error rates (need to write a CloudKick plugin) to see what effects this has, especially for mobile and poorly connected clients.
All of that said, it’s pretty cool to be able to see the effects so concretely.
BTW, one of the TODOs for htracr is to gather these metrics automatically and show better TCP-layer statistics.
Looking for Pipelining
One of the main reasons I threw htracr together was to have a look at how HTTP pipelining happens “in the wild,” so that we can make it better. I’m still working through some bugs, and need to find an effective way to visualise the relationships between requests and responses, but even so, we’re still able to see a few interesting things.
Opera is well-known for being the only browser that has pipelining turned on by default. However, from what I’ve seen so far, it’s so conservative about it, it might as well not:
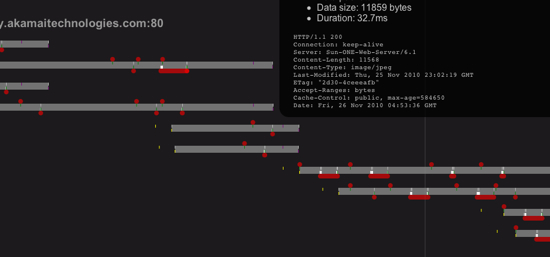
This is a load of nytimes.com in Opera 10.63; if you look at the second connection (grey bar) down, you’ll see that the last two requests are pipelined. The many others on the page aren’t, however.
Firefox 3.6 is a bit better, when you turn pipelining on:

Here, you can see a few different requests are pipelined (the brighter red dots denote nearly simulataneous messages). Things with Firefox should get even more interesting when Patrick’s patches land, of course.
These Requests Need to Go on a Diet
New York Times, front page load:

The only thing I’ll add here is that these are mild compared to some bloated requests you’ll see out there.
Pushy Servers
Another interesting thing to observe is when servers send TCP PSHs, because that usually indicates when the application write()s something.
A pathological case is Google News:
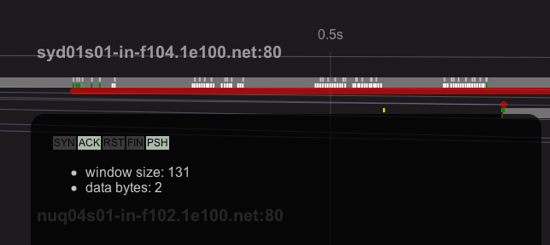
At first, it looks like they’re starting with a large cwin, but if you examine all of those green PSH packets at the start, you’ll find they’re very small, with payloads like 3, 6, and 10 bytes. This is gzipped data (it’s the gnews home page), and since the first byte isn’t seen until more than ten times the RTT, I don’t think they’re doing this for performance reasons; either it’s an artefact of their gzip implementation, or they’re doing an experiment (in typical Google style).
That’s all for now; I’m going to keep on refining htracr, trying to surface more information. Patches / github pulls welcome.
P.S. Node.JS rocks.
UPDATE: htracr is now packaged with npm, so installing it should be a snap now.
2 Comments
https://www.google.com/accounts/o8/id?id=AItOawmeSw3RMdpvkff6X4HOE3Z6Z80oN1yanjY said:
Monday, November 29 2010 at 6:58 AM
Mark Nottingham said:
Monday, November 29 2010 at 7:58 AM