
Exploring Header Compression in HTTP/2.0
Friday, 4 January 2013
One of the major mechanisms proposed by SPDY for use in HTTP/2.0 is header compression. This is motivated by a number of things, but heavy in the mix is the combination of having more and more requests in a page, and the increasing use of mobile, where every packet is, well, precious. Compressing headers (separately from message bodies) both reduces the overhead of additional requests and of introducing new headers. To illustrate this, Patrick put together a synthetic test that showed that a set of 83 requests for assets on a page (very common these days) could be compressed down to just one round trip – a huge win (especially for mobile). You can also see the potential wins in the illustration that I used in my Velocity Europe talk.
However, the CRIME attack made SPDY’s gzip-based compression a non-starter, at least for TLS-protected HTTP/2. So, a variety of folks have been proposing alternate compression schemes. To help evaluate them, I took Roberto’s test suite and tweaked it a bit to generalise it into a generic test harness; by using the HAR samples previously generated, we can get an idea of how each compressor behaves in semi-real conditions. It’s early days, but we already have a few candidates to compare:
- http1 - classic HTTP/1.1 textual encoding
- spdy3 - the gzip-based encoding proposed by SPDY. Note that it’s vulnerable to CRIME.
- delta - Roberto’s huffman-based delta encoding
- ” simple” - Omitting headers repeated from the last message, tokenising common field names, and a few other tweaks. Otherwise, it looks like HTTP/1.
I put “simple” in the mix just to demonstrate how to define a new compressor, and to exercise the system. It isn’t a serious proposal.
When you run the tool, you get output that looks something like this:
$ ./compare_compressors.py -c delta -c simple=seven -c spdy3 ~/Projects/http_samples/mnot/facebook.com.har
WARNING: spdy3 decompression not checked.
* TOTAL: 117 req messages
size time | ratio min max std
http1 44,788 0.02 | 1.00 1.00 1.00 0.00
delta 7,835 0.43 | 0.17 0.02 0.70 0.07
simple (seven) 11,770 0.02 | 0.26 0.14 0.64 0.08
spdy3 6,191 0.00 | 0.14 0.06 0.68 0.06
* TOTAL: 117 res messages
size time | ratio min max std
http1 43,088 0.00 | 1.00 1.00 1.00 0.00
delta 12,135 0.46 | 0.28 0.12 0.61 0.08
simple (seven) 14,010 0.07 | 0.33 0.16 0.63 0.10
spdy3 9,651 0.01 | 0.22 0.07 0.64 0.07
here, you can see how crazy efficient the gzip-based SPDY algorithm is, and how closely delta matches it; delta has an overall compression ratio of 17% of the raw HTTP1 size for requests, 28% for responses. Not bad.
The “simple” algorithm, on the other hand, clocks in at 26% and 33%, respectively. On other samples, it hovers around somewhere between 25 and 40%.
Another view that you can produce with the “-t” flag is a set of TSV files that are suitable for feeding in to a HTML+ d3-based visualisation, like this:
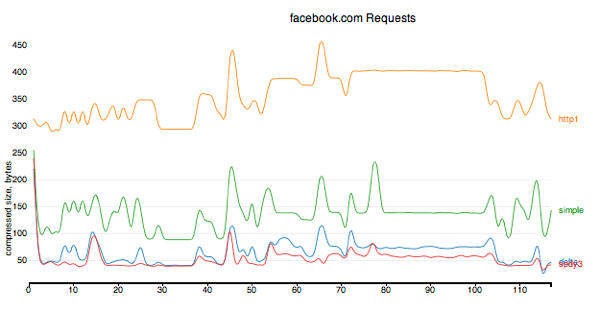
Here, the y-axis is the size of the response, in bytes, and the x-axis is the series of messages (request or response) involved in navigating the site. See the full set of graphs for the current set of traces we have, showing the results for all of the algorithms explained above.
What’s Already Apparent
Like I said, it’s early days; we’re just developing the proposals, and the testbed itself is still rapidly changing (see below). However, looking at these early results, a few things are already becoming clear:
**Sites vary greatly in terms of header size, as well as changing over their lifetime. ** Take a look at the full set of graphs and compare how consistent the Flickr request and responses are over time, compared to the wild fluctuation of the Yahoo results (and notice the difference in scales!). See also the steady growth at the end of Yandex’s requests.
HTTP headers are indeed massively redundant. The “simple” algorithm isn’t a serious proposal, and it still manages to save somewhere around 65% of most messages; sometimes much more. This says that there are a lot of headers that just get mindlessly repeated on a connection. This is the low-hanging fruit; I think the question at hand is how much higher we reach, and what we trade off for it.
SPDY3’s compression is the one to beat for efficiency. This isn’t terribly surprising, because it’s essentially just gzip, and gzip is a proven algorithm.
How You Can Help
We’re having an interim meeting at the end of the month, and doubtless one of the major topics will be header compression. If you’d like to help, you can:
Submit some traces - right now, we have a set of traces I captured while navigating three or four times on a handful of popular Web sites. The Web is much bigger than this, obviously, so we need more traces. See the repository to learn how.
Propose a compression algorithm - we have a few, but there’s no reason you can’t add yours to the mix. Ideally this would involve writing an Internet-Draft, but there’s no reason you can’t fork the repository and have a play.
Improve the code - I have a number of planned improvements; I’d like to get more meaningful numbers out of it, and make the stream of requests fed to the compressors to be more realistic (right now, it’s just blatting everything from the HAR straight in, as if they all used the same connection). Help with these would be much appreciated; on the other hand, if you can help present the data more meaningfully, that would be great too. And, of course, issue reports are welcome.